Due to the large number of pages involved, ecommerce sites can see striking SEO improvements when errors on those pages are addressed. Let’s talk about what you need to do in order to keep your ecommerce site error free, starting with some tools, then walking you through some processes.
Monitoring and crawling tools
Monitoring and crawling tools are necessary in order to identify technical SEO errors. I consider the following tools essential:
- ScreamingFrog: This is, hands down, one of the best SEO spider available out there for most uses. You will need this, or something very similar, to handle most of the errors we will be discussing in this post.
- Google Search Console: Make sure you set up an account here for your domain, since it will notify you of errors that crawlers won’t necessarily be able to find.
- Google Analytics: Check your analytics regularly for unexpected drops in organic search traffic, since these can point you to errors that you won’t necessarily find otherwise.
I also recommend using these tools to check for SEO various issues:
- W3C Validator: Use this to validate the code on your homepage and page templates. You want to ensure your HTML is valid so the search engines can read it properly. Use it to validate your XML sitemaps as well.
- WebPageTest: Use it to test how fast your pages are loading and which elements on your pages contribute the most to slowing down the site load.
- MxToolBox DNS Check: Check for any DNS issues and talk to your host about any errors you find here.
- Pingdom: Monitors your site uptime so you are notified if your site isn’t loading or has reliability issues.
- SSL Labs Test: Make sure your SSL is working properly and isn’t deprecated.
404s (missing pages)
Missing pages hurt the user experience for obvious reasons, but they also hurt your SEO. Links that point to 404 pages throw away their authority.
To identify 404 pages, start by running a site crawl in ScreamingFrog. After finishing the crawl, go to “Response Codes,” then select “Client Error (4xx)” from the “Filter” dropdown menu.

Now export the list for later.
These are your high priority 404 errors, because they are missing pages that have been linked to from other pages on your own site.
For each page, identify whether there is a suitable replacement. If so, you will need to run a search and replace operation on your site to replace all references to the 404 page with the suitable replacement.
If there are no suitable replacements, you will need to remove links to the page so that there are no more broken links.
Additionally, you will need to set up 301 redirects from the missing pages to their replacements.
Do not merely set up 301 redirects without updating the links. Links that pass through 301 redirects lose some SEO authority to Google’s damping factor, and redirects put load on your servers.
Next you will need to identify your “lower priority” 404 pages. These are missing pages that you aren’t linking to from your own pages, but that other sites are linking to. This could be the result of old pages that you have removed, or it could be that the sites linking to you used the wrong URL.
You can find these in the Google Search Console by going to “Crawl” followed by “Crawl Errors” in the left navigation:

Choose “Not Found” and export your 404s.
Weed out the duplicate 404s that you have already addressed from ScreamingFrog. Now identify if any of these have a suitable replacement. If so, set up a 301 redirect to send users to the appropriate page.
Do not simply set up an all-encompassing rule to redirect all visits to missing pages so that they go to the homepage. This is considered a soft 404. Google does not like them, and they are the subject of our next section.
Soft 404s
A soft 404 is a missing page that doesn’t show up as a 404 to Google. Google explicitly warns against soft 404s, which come in two forms:
- “Page Not Found” pages that look like 404s to users, but that return a success code and are indexable by the search engines.
- 301 or 302 redirects to unrelated pages, such as the homepage. A redirect is meant to send users to the new location of a page, not to an off-topic page that will disappoint them.
Too many of either will hurt your authority with the search engines.
You can find soft 404s in the Google Search Console, also within the “Crawl Errors” section.
To resolve soft 404s, you may:
- Remove a site-wide redirect policy that redirects all visits to missing pages to the homepage
- Ensure that your missing pages properly return 404 status codes.
- Institute a page-specific redirect if a suitable replacement is available.
- Re-institute the page so that it is no longer missing. If you don’t know what was previously at the URL, you can use the Wayback Machine to see what used to be on the page, assuming it was crawled.
- Allow the page to return a 404 status code if there are no suitable replacements, but be sure you are not linking to the page anywhere on your own site.
Do not get greedy with your redirects in an effort to capture PageRank, or you will send a message to the search results to treat your 301 pages like 404s.
Redirects
Before tackling anything else, you want to ensure that your site does not have any redirect chains or loops. These are series of redirects, where one redirect leads to another, etc. This bleeds PageRank through Google’s damping factor and creates server load. Redirect loops make pages inaccessible.
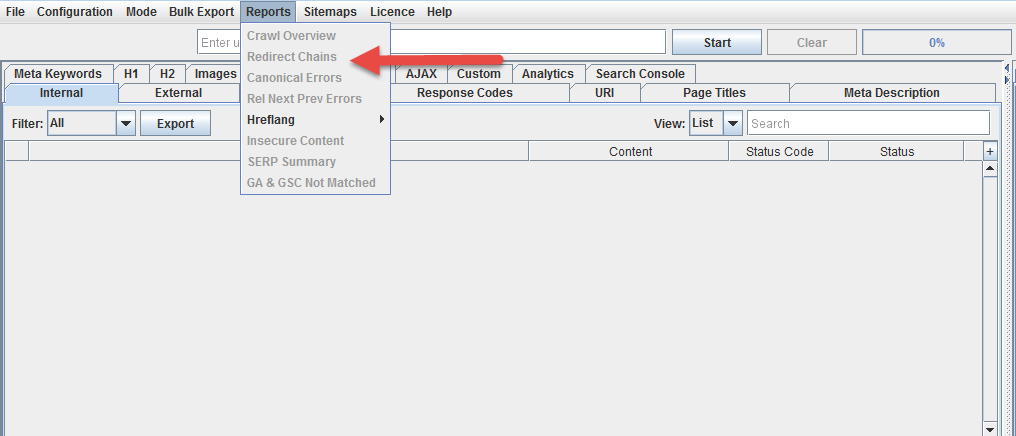
Replace any redirect chains with redirects directly from the relocated page to the new location.
Once you’ve addressed this, use ScreamingFrog to identify your 301 and 302 redirects.

Start by addressing your 302 redirects, since these are supposed to be temporary. If any of them are actually permanent, they should be changed to 301 redirects so that the redirected page doesn’t remain in the index. Checking your 302s can also serve as a reminder to remove temporary redirects and reinstate forgotten pages.
After handling your 302s, the next step is to remove any links to redirected pages from your site, and replace them with links to the correct location. There are very few circumstances in which you actually want to link to a redirected page, since PageRank is lost through the redirect and server load is created. Use a search and replace operation to accomplish this.
Canonicalization
Canonicalization is a method of dealing with duplicate pages, which are very common for ecommerce sites. Canonicalization tells the search engines which version of the page to treat as the legitimate one. We talked about it in detail in our ecommerce SEO guide here, but these are some guiding principles:
- Use canonicalization to address any URL variables that re-sort or filter the content without otherwise changing it.
- Canonicalize any pages that are duplicated because they are listed in multiple categories.
- Any paginated content should be canonicalized to a non-paginated full version.
- Pages that are personalized based on the user should canonicalize to a non-personalized version.
To identify pages that may need canonicalization, use ScreamingFrog to identify duplicate title tags:
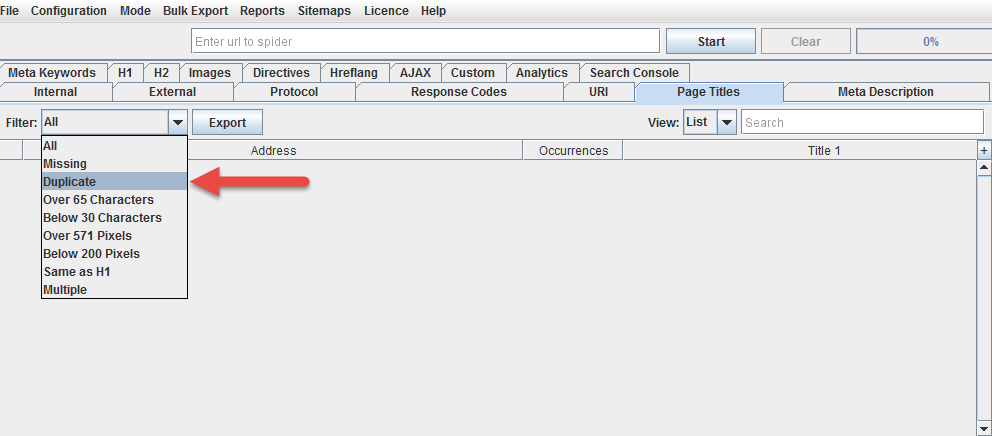
These are very often, though not always, duplicates of the same page.
Noindexing
Many ecommerce sites often have thousands or more pages, and quite a few of them may be very low in quality or content. Many may be very similar to one another without being pure duplicates. Many may feature manufacturer copy that is identical to what will be found on other ecommerce sites.
In some cases, then, it is a good idea to noindex some of your pages. Noindexing tells the search engines to remove the page from the search results. The noindex tag is thus a very dangerous toy to play with, and it’s important not to overuse it.
Here are a few pages that should definitely be noindexed:
- Any admin or membership areas
- Any part of the checkout system
- “Thank you” or payment confirmation pages
- Internal search results
A few warnings:
- Never use “nofollow” on your own links or content. Always use <META NAME=”ROBOTS” CONTENT=”NOINDEX, FOLLOW”>. The “nofollow” tag tells the search engines to throw away your PageRank. It is never a good tag to use on your own content.
- Do not canonicalize and noindex a page. Google has warned explicitly against this. In a worst case scenario this will noindex your canonical page, even if the noindex tag is only on the duplicates. More likely, it will treat the canonical tag as a mistake, but this means any authority shared between the duplicates will be lost.
HTML compliance
We mentioned earlier that you should run the W3C validator on your homepage and template pages to ensure you don’t have any serious html errors. While html errors are common and Google is fairly good about dealing with them, it’s best to clean up errors to send the clearest message possible to the search engines.
Use batch validation to check a larger number of pages.
Schema.org
Schema is a must for ecommerce sites because it allows you to feed the search engines useful meta data about your products like user ratings and prices that can lead to rich results in the search engines featuring star ratings and other stand out features.
Review Google’s literature on rich results for products and include the proper schema to make it work. This schema code generator is useful for easily putting together the code for your templates, and you can test if your pages properly support rich results using Google’s own tool here.
Conclusion
Technical SEO is important in any industry, but due to the massive size of ecommerce sites, it is even more relevant for retailers. Keep your errors under control and your organic search traffic numbers will thank you.
No comments:
Post a Comment